pRETzel logic
サイボウズ・ラボユース11期 成果物
ラボユースの11期生としてやってきたことの紹介をします.
theme
LLVMを利用した難読化コンパイラの実装
- LLVMに実装することで多種多様なアーキテクチャ/言語に対応できる(はず)
- ROPを難読化に活用する
- バイナリ変換ではなくコンパイラのレイヤーでアプローチすることで他の難読化手法との組み合わせも可能
about
ROP(Return Oriented Programming)による難読化
ROP
returnによる状態遷移でプログラミングを行う
主にexploitの文脈で使われている手法で,実際CTFの最中にこの難読化手法は思いついた.
バイナリを解析する際に重要なのが
「コンパイル済のバイナリから,元のソースコードに近い情報を導き出すこと」
解析時には主に制御フロー(Controll Flow)を辿るような手順が多い.
具体的には,jmp/call/ret等の命令による遷移を辿っていく.
ROPによりそれらの命令を置換することで,CFGが破壊され,難読化につながる.
Prior Research
最初に思いついた時は天才かと思ったが,既に天才は何人かいた.
一方,どの論文を読んでもバイナリを変換するようなアプローチばかりな上,実装は公開されていなかった.
コンパイラ基盤上に実装することで,より柔軟な(例えば関数毎の)適用や,他の難読化手法との組み合わせもより自由になる.
implementation
X86
x86ではreturn addressはスタックに積まれている.
これを利用し,遷移したいアドレスをスタックに積んでからret命令を発行する事で任意の操作が可能になる.
jmp label
例えば,このような遷移を難読化すると
sub rsp, 0x8
push rax
lea rax, label
mov [rsp+0x8], rax
pop rax
ret
のような形になる.
AArch64
一方,armの場合はretで遷移するアドレスはスタックに積まれている訳では無い.
リンクレジスタと呼ばれるレジスタ(lr(x30))が使われるため,実質br lrと同じような挙動となる.
その性質上,aarch64の呼び出しを難読化する際はcalleeにも手を加える必要がある.
b label
~ snip ~
label:
~ snip ~
x86で言う所のjmpに近い命令を難読化しようとすると,
caller
sub sp, sp, #8
str x30, [sp, #0]
adr x30, %rop_label
ret
callee
label:
sub sp, sp, #8
str x30, [sp, #0]
rop_label:
ldr x30, [sp, #0]
add sp, sp, #8
このように,リンクレジスタの復元処理が必要になる.
LLVM
コンパイラ基盤
各種アーキテクチャに対応している
最適化や解析等の処理をPassという単位に分けて適用する.
Obfuscation Pass
今回は難読化処理をPassとして実装し,適用する.
LLVMではアーキテクチャに依存しないIRから,ターゲット特有の表現へ変換し,最終的にバイナリを生成する.
目的の処理はアーキテクチャ毎に異なるため,IRから変換された後のデータに対して適用されるPassを実装している.
demo
例として,フィボナッチ数を求める簡単なプログラムを難読化してみる.
#include <stdio.h>
int fibdp[100];
int fib(int n) {
if (n == 0 || n == 1) {
return n;
} else if (fibdp[n] != 0) {
return fibdp[n];
} else {
fibdp[n] = fib(n-2) + fib(n-1);
return fibdp[n];
}
}
int main() {
for (int i = 0; i < 100; i++)
fibdp[i] = 0;
int ans = fib(46);
printf("%d\n", ans);
return 0;
}
難読化無しでコンパイルしたバイナリから,静的解析ツールを利用してCFGを生成してみると
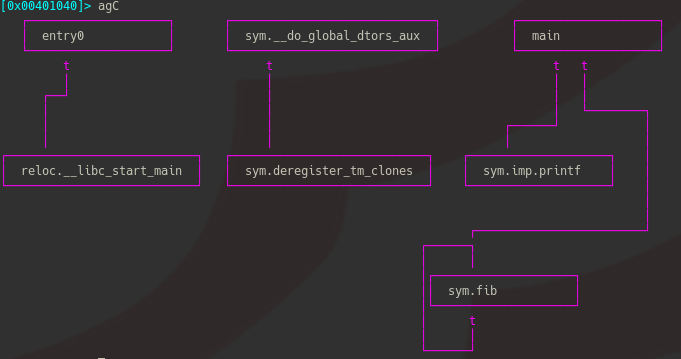
mainからの呼び出しやfibの再帰等が一目瞭然
一方,難読化を有効化すると
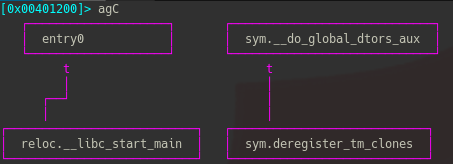
mainの存在ごときれいに消えている.
なぜmainは消えたのか
ツールの気持ちになってみる
バイナリから関数を解析する際,基本的にはシンボルからretまでを一つのブロックとして認識している.
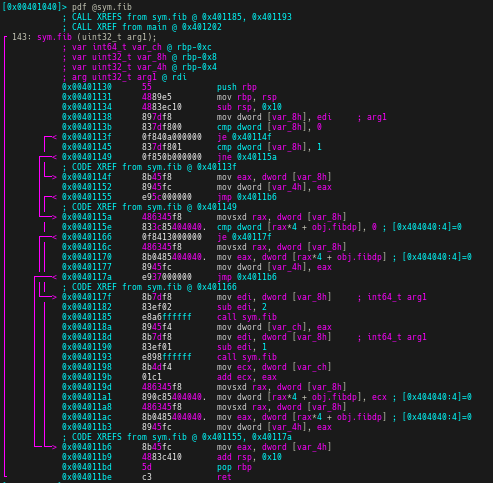
しかし,ROPにより,通常より早い段階でretが発行され,関数の終端が誤認される.
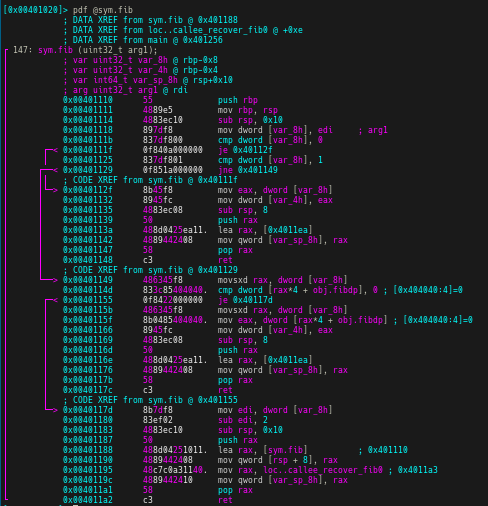
結果,デコンパイル結果等も破壊される
default
[0x00401040]> pdg @sym.fib
// DISPLAY WARNING: Type casts are NOT being printed
uint32_t sym.fib(uint32_t arg1)
{
int32_t iVar1;
int32_t iVar2;
uint32_t var_8h;
uint32_t var_4h;
var_4h = arg1;
if ((arg1 != 0) && (arg1 != 1)) {
if (*(obj.fibdp + arg1 * 4) == 0) {
iVar1 = sym.fib(arg1 - 2);
iVar2 = sym.fib(arg1 - 1);
*(obj.fibdp + arg1 * 4) = iVar1 + iVar2;
var_4h = *(obj.fibdp + arg1 * 4);
}
else {
var_4h = *(obj.fibdp + arg1 * 4);
}
}
return var_4h;
}
obfuscated
[0x00401020]> pdg @sym.fib
// DISPLAY WARNING: Type casts are NOT being printed
uint64_t sym.fib(uint32_t arg1)
{
uint32_t var_8h;
uint32_t var_4h;
if ((arg1 != 0) && (arg1 != 1)) {
if (*(obj.fibdp + arg1 * 4) != 0) {
return *(obj.fibdp + arg1 * 4);
}
return arg1;
}
return arg1;
}
難読化を施しても通常の動作に支障は無いが,オーバーヘッドはゼロではない.
試しに大量の素数を計算するサンプルで計測してみると
$ hyperfine --warmup 3 ./prime_rop ./prime_default
Benchmark 1: ./prime_rop
Time (mean ± σ): 8.419 s ± 0.048 s [User: 8.416 s, System: 0.001 s]
Range (min … max): 8.347 s … 8.482 s 10 runs
Benchmark 2: ./prime_default
Time (mean ± σ): 7.866 s ± 0.029 s [User: 7.865 s, System: 0.001 s]
Range (min … max): 7.830 s … 7.903 s 10 runs
Summary
'./prime_default' ran
1.07 ± 0.01 times faster than './prime_rop'
大体7%ほどの速度低下となっている
prospect
x86とaarch64への対応はできている.
RISC-Vを始めとした,LLVMが対応している各種アーキテクチャに対応したい.
アーキテクチャ以外の点では,他の難読化手法との融合が考えられる.
既に定数難読化などは実装したので,組み合わせる事もできる.
compact
よりコンパクトに,Pass単体でのビルドができる形に整備したい.
repository
github.com/n01e0/pRETzel_logic
Comments